머신러닝에서 정확도, 재현율, 정밀도 이 3가지 값은 모델의 정확함을 설명하는 매우 중요한 지표이다. 그런데! 애석하게도, 상시로 이 지표를 접하지 않으면 그 뜻을 잊어버리기 쉽게 된다. 물론 자주 쓰면 안그러는데, 그렇지 않거나 특정 지표를 오랫동안 안사용하다보면 헷갈린다. 그래서 이 글을 시작해본다.

자 이제 사기꾼을 잡아보자. 어떤 행동을 보고 사기꾼을 잡는 방식이다. 이것을 위해 머신러닝 모델을 하나 만들었고, 1,000명을 검사해서 실제 잘 맞췄는지 아닌지 결과를 확보했다. 이 모델은 얼마나 정확할까?
아주 편안하고 쉽게 이 질문에 답해보면 단순하게 할 수 있다. 정확도(Accuracy)가 그 첫번째 지표이다.
1,000명을 검사했으니 그 중에 몇명을 정확히 맞췄는지 그 비율을 이야기하면 된다.
Accuracy = 정답수 / 전체 검사수
검사 대상 1,000명이 실제 일반인인지 사기꾼인지 알고 있다고 가정하고, 모델이 판정한 결과와 비교해보면 맞은 것과 틀린 것이 있을 것이고, 1,000명 중에 실제 몇 건이 맞았는지 비율을 보면 되지 않겠는가? 그렇게 간단히 끝날 수 있겠다.
그런데 이건, 사기꾼과 일반인이 같은 비율로 존재할 때의 이야기이다. 소위 이야기하는, 분류 문제에서 사전 확률(Prior Probability)이 같으면 문제가 쉽고 지표도 간단하다. 그런데 세상 대부분의 문제에서 이 사기꾼과 일반인의 비율이 많이 다르다.
1,000명 중에 실제 사기꾼이 3명이 존재하는 문제라고 치자. 그러면 이 정확도를 올리기 위해 좀 꼼수를 피워서, 모든 검사 대상을 일반인으로 강제로 판단하게 만들었다고 가정해보자. 이 엉터리 모델의 정확도는 얼마일까?
Accuracy = 정답수 / 전체 검사수 = 997 / 1,000 = 99.7 %
아니 이런! 모든 사람을 일반인으로 판단하는 엉터리를 만들었는데도 일반인이 997명이다 보니, 정확도가 99.7%이다. 무언가 단단히 잘못된 정확성 지표라고 볼 수 있다. 이 모델은 어떤 사기꾼도 잡아낼 수 없는데, 정확도가 99.7%라니! 무능한 모델에게 너무 높은 수치가 주어지는게 아닌가?
그래서 이렇게 소수의 사기꾼을 잡는 문제에 있어서 매우 유용한 지표가 필요하다. 바로 재현율(Recall)이다. 이 녀석은 전체 사기꾼 3명 중에 몇명을 실제로 사기꾼으로 판정하느냐를 나타낸다. 전체 검사수에서 사기꾼이 적다는 점을 이용해 엉터리로 모든 검사 결과를 일반인으로 판정해버리는 모델을 골라내는 지표이다. 이를 정의하는 것은, 앞서 전체 사기꾼 중 몇명을 실제로 잡느냐로 나타내면 된다. 전체 사기꾼 중에 아무도 못잡으면 바로 0%가 되는 지표이다.
Recall = 찾은 사기꾼 / 전체 사기꾼
이제 조금씩 어려워진다. 1,000명 중에 실제 사기꾼이 3명인데, 어떤 모델로 검사를 했더니 900명은 일반인으로 판정했으나, 그 중 1명은 사실은 사기꾼이었고, 100명은 사기꾼으로 판정했는데, 그중 98명은 일반인이었다고 치자. 그러면 이 헷갈리는 상황을 아래의 4종류의 수치로 간결하게 분할 할 수 있다.

여기 Recall을 구해보면
Recall = 사기꾼이라 판정 / 실제 전체 사기꾼 = 2 / (2+1) = 약 66%
이 된다. 이 모델은 Accuracy는 (2+899) / 1,000 = 90.1% 이면서 Recall은 66%인 모델이다.
그러면 이 모델의 판정기능을 좀 조율하면 어떤 일이 벌어질까? 예를 들면 사기꾼을 좀더 일반인으로 판정해버리는 것이다. 대충 사기꾼이어 보여도 무시하고 일반인으로 판정해주자. 그러면 Accuracy는 올라가고 Recall은 떨어질 것이다. 즉, 모델 튜닝에 의해 이 2가지 값은 서로 반대로 향하게 된다. 그래서 이 수치를 밸런싱하는 작업도 또한 모델 튜닝의 중요한 작업이다.
그런데 이 상황에서 우리가 이 모델을 가지고 실제 일을 할때 경험하는, 현실에 계속 마주하게 되는 또다른 수치가 하나 있다. 바로 사기꾼이라고 검출한 것 중에 과연 얼마나 실제 사기꾼일까 하는 비율이다. 왜냐하면, 일단 모델이 일반인으로 분류된 사람들은 집에 보낼테고, 사기꾼이라고 분류한 사람들 중에 세부 검사를 하게 될테니까 말이다. 실제 이 모델은 그렇게 쓰이는게 일반적이다. 그래서 이 수치가 매우 높으면 거의다 사기꾼이 맞기 때문에 골치아픈 일이 적다. 그런데 이 비율이 낮으면 대부분 잘못 판정한 것이기 때문에 고생을 하게 될 것이다. 바로 이 수치가 정밀도(Precision)이다.
Precision = 실제 사기꾼으로 잘 판정된 수 / 사기꾼이라 판정 = 2 / (2+98) = 2%
그렇다 위 모델은 정확도는 90.1%로 뭐 그럭저럭 나와보이고, Recall은 66%로 전체 사기꾼 중에서도 꽤 잡아내지만, 실제 우리가 일할때는 2%의 Precision을 가지는 형편없는 모델인 것이다. 막상 사기꾼이라고 100명이나 나왔는데, 그 중에서 2명만 실제 사기꾼인 그다지 쓸모가 없는 모델이다.
이 세가지 수치가 모델을 평가하고, 실제 일을 할때 중요하게 다뤄지는 정확도에 관한 수치이다. 그러면 이걸 통계학에서 들었던 것과 매핑해서 다시 정리해보면 어떨까? 위 1,000명의 전체 결과 지도를 그대로 매핑해서 나타내보자. 이것이 바로 우리가 통계학에서 배웠던 TP(True Positive), FP(False Positive, Type II Error), FN(False Negative, Type I Error), TN(True Negative) 이며 아래가 바로 그 값들이다. 그리고 그 정확성을 나타내는 지표를 각각 옆에 나타내었다.
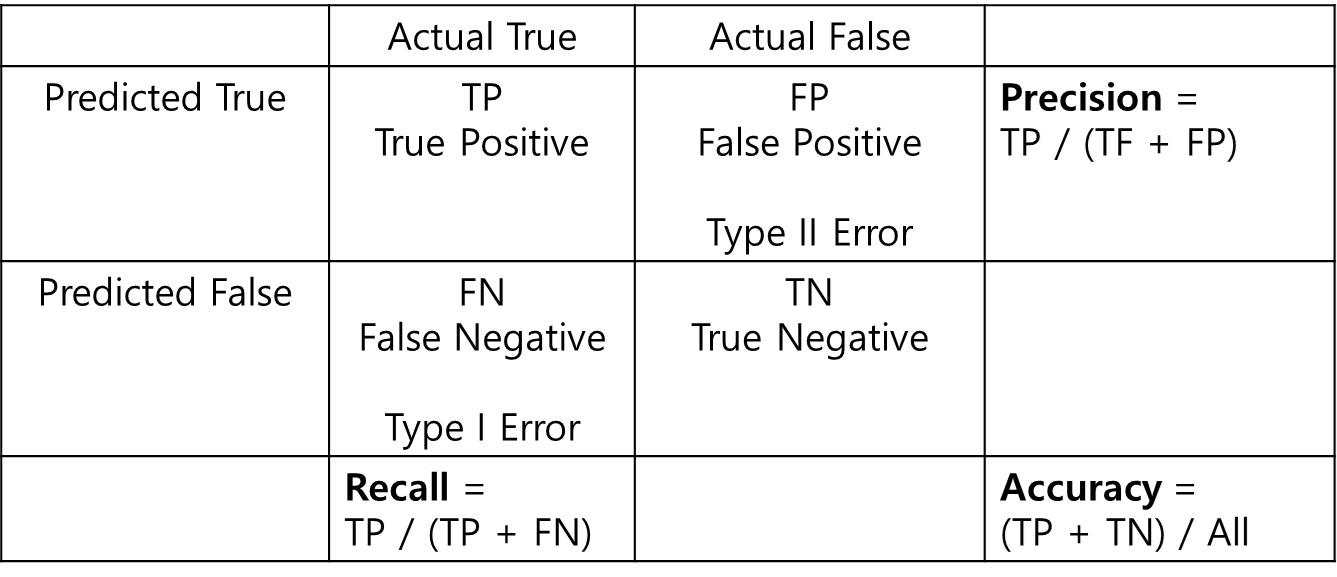
이렇게 기억을 해보자. Accuracy+Recall과 그 다음 실제 일을 할때 마주하는 Precision말이다.
그리고 보너스가 있다. 바로 F1 score인데, 이 값은 Precision과 Recall의 조화평균이다. 그렇다. 일반인이 일반인으로 잘 판정되는건(True Negative) 관심도 없고, 다만 나머지들을 가지고 만든 지표 둘인 Precision과 Recall이 조화를 이룬 수치다. 지나고 나면 이 사기꾼 잡는 모델에 있어서 Accuracy는 제일 관심없는 정확성 지표일지도 모르겠다.
'머신러닝AI' 카테고리의 다른 글
| ChatGPT가 보여주는 AGI의 가능성은? (0) | 2023.02.26 |
|---|---|
| ChatGPT는 스카이넷이 될 수 있을까? (0) | 2023.02.19 |
| 정말 인류가 인공지능을 만드는 것은 가능할까? (0) | 2022.10.10 |
| 사람을 닮은 지능/AI의 문제에서 진화가 중요한 이유는? (0) | 2022.01.09 |
| 신경망이 가중치를 임의로 부여해도 지능을 쉽게 갖게 되는 구조인가? (0) | 2021.01.07 |
